The importance of detecting patterns
A student whose M.S. thesis project I have followed in the last months has recently handed out his final thesis report. We have spent some time talking about his work, what parts of it he liked most, and what he had learned from this experience. The project turned out to be quite appreciated (this is one of the papers that we published with him) and I was glad to hear that he liked a lot the part involving scraping. He has also gained quite much experience about the topic, enough to find its weakest parts (i.e. relying only on regexps to extract page contents is bad, as some kind of pages change pretty often and you might need to rewrite them each time) and its most interesting generalizations. During our talk, he told me that one of the most impressive things for him was that websites belong to families, and if you can spot the common patterns within a family you can write general scrapers that work well with many sites.
Actually, this is not such an amazing piece of news, but that's SO true that I felt it was worth to spend some time over it. I have been experimenting this concept on my skin, while I was writing one of my first crawlers: it was called TWO (The Working Offline forum reader, a name which tells much about my previous successes in writing scrapers ;)) and its purpose was to fully download the contents of a forum inside a DB, allowing users to read them when offline. This tool relied on a set of plugins which allowed it to work with different forum technologies (I was supporting PhPBB, VBulletin, and a much less standard software used for some very specific forums about reversing and searching). Of course, what I noticed while writing it is that all forums could be roughly described in the same way: every forum has some threads, every thread has different messages, and every message has specific properties (Author, Date, Subject, Message body) that are repeated throughout the system. Having different systems complying to the same standards provides some advantages:
- crawlers are usually built over two main components: a "browsing component" that deals with finding the right starting pages and following the right links in them, and a "scraping component" that deals with extracting relevant page contentes. We can exploit browsing patterns to use the same browsing component for crawling different websites/systems. For instance, we know that in every main forum page we will follow some links (with a format that can be specified with a regexp) to access different sub-forums containing lists of threads, and then we will access one or more pages with the typical "list" pattern (go to first, last, previous, or next page);
- similarly, we can exploit scraping patterns to use the same data structures for objects retrieved from different sources. For instance, we can create a "forumMessage" object whose attributes are the message content, the subject, the date, and the author, and these will hold for all the messages we get from any website;
- being able to bring together, in the same objects, homogeneous types of information from heterogeneous sources allows us to automatically analyze it, bringing some new knowledge out. For instance, if we know we have a "rating" field in two websites which is comparable (i.e. uses a compatible range of values, or can be normalized), then we can calculate an average of this rating over different services (a value that most of websites, competing one with each other, will never give you).
To give you a practical example, I have applied this concept on search engines to write a simple but very flexible search engine aggregator. I needed to get results from different search engines, merge them, and calculate for instance in how many different domains results could be grouped, which engine returned more results, and so on. I made some example searches with google, yahoo, bing, and others, and described the general access patterns as follows:
- first of all, a user agent connects to the search engine at a specified address (in most of the cases it is the default s.e. domain, but sometimes you might want to force a different URL, i.e. to get results in a given language and not the default one according to your location);
- then, the main search form is filled with the search string and some parameters you want your results to comply to (i.e. number of results per page, language, date restrictions, and so on);
- when the results are returned, they are usually shown in a well defined way (i.e. easily parsable with a given regular expression) and if they do not fit in one page it is possible to follow links to the next or the following ones. If you want all the results, you just need to load the next results page until no more "next" link appears.
The result is a (well, yet another) scraper. Its input is a JSON like the following one:
{
"engines": {
"google": {
"fields": {
"num": 10,
"q": "$search"
},
"id": 1,
"next": "Next",
"nextURL": "google.com/search",
"regexp": "<a href=\"([^\"]+)\" class=l>",
"sleep": 2,
"url": "http://www.google.com/ncr"
},
"bing": {
"fields": {
"q": "$search"
},
"id": 2,
"next": "^Next$",
"regexp": "<div class=\"sb_tlst\"><h3><a href=\"([^\"]+)\"",
"sleep": 5,
"url": "http://www.bing.com/?scope=web&mkt=it-IT&FORM=W0LH"
},
"yahoo": {
"fields": {
"n": 10,
"p": "$search"
},
"id": 3,
"next": "^Next",
"regexp": "<a class=\"yschttl spt\" href=\"([^\"]+)\"",
"sleep": 5,
"url": "http://www.yahoo.com"
}
},
"search": {
"1": "\"Davide Eynard\"",
"2": "aittalam",
"3": "3564020356"
}
}
As you can see, all the search engines are described in the same way (miracles of patterns :)). Each one of them has a name and an id (used later to match it with its own results), a URL and a set of input fields, a sleep time (useful if anyone tries to ban you because you are hammering it too much), plus regular expressions to parse both the single URLs returned as results and the "Next" links inside result pages. To test the scraper, download it here. Pass it the text above as input (either by pasting it or by saving it in a file and redirecting its contents, i.e. perl se.pl <testsearch.json). The scraper is going to take some time as it is querying all the three search engines with all the three search strings (I left $DEBUG=1 to allow you to see what is happening while it runs). At the end you'll be returned another JSON file, containing the results of your combined search: a list of all the matching URLs grouped by domain, together with the search engine(s) that returned them and their ranking.
Of course, this is just a skeleton app over which you can build something much more useful. Some examples? I have used a variation of this script to build a backlink analysis tool, returning useful statistics about who is linking a given URL, and another one to get blog posts about a given topic that are later mined for opinions. Hope you got the main teaching of this story: patterns are everywhere, it's up to you to exploit them to make something new and useful ;)
WOEID to Wikipedia reconciliation
For a project we are developing at PoliMI/USI, we are using Yahoo! APIs to get data (photos and tags associated to these photos) about a city. We thought it would be nice to provide, together with this information, also a link or an excerpt from the Wikipedia page that matches the specific city. However, we found that the matching between Yahoo's WOEIDs and Wikipedia articles is far from trivial...
First of all, just two words on WOEIDs: they are unique, 32-bit identifiers used within Yahoo! GeoPlanet to refer to all geo-permanent named places on Earth. WOEIDs can be used to refer to differently sized places, from towns to Countries or even continents (i.e. Europe is 24865675). A more in-depth explanation of this can be found in the Key Concepts page within GeoPlanet documentation, and an interesting introductory blog post with examples to play with is available here. Note that, however, you now need a valid Yahoo! application id to test these APIs (which means you should be registered in the Yahoo! developer network and then get a new appid by creating a new project).
One cool aspect of WOEIDs (as for other geographical ids such as GeoNames' ones) is that you can use them to disambiguate the name of a city you are referring to: for instance, you have Milan and you want to make sure you are referring to Milano, Italy and not to the city of Milan, Michigan. The two cities have two different WOEIDs, so when you are using one of them you exactly know which one of the two you are talking about. A similar thing happens when you search for Milan (or any other ambiguous city name) on Wikipedia: most of the times you will be automatically redirected to the most popular article, but you can always search for its disambiguation page (here is the example for Milan) and choose between the different articles that are listed inside it.
Of course, the whole idea of having standard, global, unique identifiers for things in the real world is a great one per se, and being able to use it for disambiguation is only one aspect of it. While disambiguation can be (often, but not always!) easy at the human level, where the context and the background of the people who communicate help them in understanding which entity a particular name refers to, this does not hold for machines. Having unique identifiers saves machines from the need of disambiguating, but also allows them to easily link data between different sources, provided they all use the same standard for identification. And linking data, that is making connections between things that were not connected before, is a first form of inference, a very simple but also a very useful one that allows us to get new knowledge from the one we originally had. Thus, what makes these unique identifiers really useful is not only the fact that they are unique. Uniqueness allows for disambiguating, but is not sufficient to link a data source to others. To do this, identifiers also need to be shared between different systems and knowledge repositories: the more the same id is used across knowledge bases, the easier it is to make connections between them.
What happens when two systems, instead, use different ids? Well, unless somebody decides to map the ids between the two systems, there are few possibilities of getting something useful out of them. This is the reason why the reconciliation of objects across different systems is so useful: once you state that their two ids are equivalent, then you can perform all the connections that you would do if the objects were using the same id. This is the main reason why matching WOEIDs for cities with their Wikipedia pages would be nice, as I wrote at the beginning of this post.
Wikipedia articles are already disambiguated (except, of course, for disambiguation pages) and their names can be used as unique identifiers. For instance, DBPedia uses article names as a part of its URIs (see, for instance, information about the entities Milan and Milan(disambiguation)). However, what we found is that there is no trivial way to match Wikipedia articles with WOEIDs: despite what others say on the Web, we found no 100% working solution. Actually, the ones who at least return something are pretty far from that 100% too: Wikilocation works fine with monuments or geographical elements but not with large cities, while Yahoo! APIs themselves have a direct concordance with Wikipedia pages, but according to the documentation this is limited to airports and towns within the US.
The solution to this problem is a mashup approach, feeding the information returned by a Yahoo! WOEID-based query to another data source capable of dealing with Wikipedia pages. The first experiment I tried was to query DBPedia, searching for articles matching Places with the same name and a geolocation contained in the boundingBox. The script I built is available here (remember: to make it work, you need to change it entering a valid Yahoo! appid) and performs the following SPARQL query on DBPedia:
SELECT DISTINCT ?page ?fbase WHERE {
?city a <http://dbpedia.org/ontology/Place> .
?city foaf:page ?page .
?city <http://www.w3.org/2003/01/geo/wgs84_pos#lat> ?lat .
?city <http://www.w3.org/2003/01/geo/wgs84_pos#long> ?long .
?city rdfs:label ?label .
?city owl:sameAs ?fbase .
FILTER (?lat > "45.40736"^^xsd:float) .
FILTER (?lat < "45.547058"^^xsd:float) .
FILTER (?long > "9.07683"^^xsd:float) .
FILTER (?long < "9.2763"^^xsd:float) .
FILTER (regex(str(?label), "^Milan($|,.*)")) .
FILTER (regex(?fbase, "http://rdf.freebase.com/ns/")) .
}
Basically, what it gets are the Wikipedia page and the Freebase URI for a place called "like" the one we are searching, where "like" means either exactly the same name ("Milan") or one which still begins with the specified name but is followed by a comma and some additional text (i.e. "Milan, Italy"). This is to take into account cities whose Wikipedia page name also contains the Country they belong to. Some more notes are required to better understand how this works:
- I am querying for articles matching "Places" and not "Cities" because on DBPedia not all the cities are categorized as such (data is still not very consistent);
- I am matching rdfs:label for the name of the City, but unfortunately not all cities have such a property;
- requiring the Wikipedia article to have equivalent URIs related with the owl:sameAs property is kind of strict, but I saw that most of the cities had not only one such URI, but also most of the times the one from Freebase I was searching for.
This solution, of course, is still kind of naive. I have tested it with a list WOEIDs of the top 233 cities around the world and its recall is pretty bad: out of 233 cities the empty results were 96, which corresponds to a recall lower than 60%. The reasons of this are many: sometimes the geographic coordinates of the cities in Wikipedia are just out of the bounding box provided by GeoPlanet; other times the city name returned by Yahoo! does not belong to any of the labels provided by DBPedia, or no rdfs:label property is present at all; some cities are not even categorized as Places; very often accents or alternative spellings make the city name (which usually is returned by Yahoo! without special characters) untraceable within DBPedia; and so on.
Trying to find an alternative approach, I reverted to good old Freebase. Its api/service/search API allows to query the full text index of Metaweb's content base for a city name or part of it, returning all the topics whose name or alias match it and ranking them according to different parameters, including their popularity in Freebase and Wikipedia. This is a really powerful and versatile tool and I suggest everyone who is interested in it to check its online documentation to get an idea about its potential. The script I built is very similar to the previous one: the only difference is that, after the query to Yahoo! APIs, it queries Freebase instead of DBPedia. The request it sends to the search API is like the following one:
where (like in the previous script) city name and bounding box coordinates are provided by Yahoo! APIs. Here are some notes to better understand the API call:
- the city name is provided as the query parameter, while type is set to /location/citytown to get only the cities from Freebase. In this case, I found that every city I was querying for was correctly assigned this type;
- the mql_output parameter specifies what you want in Freebase's response. In my case, I just asked for Wikipedia ID (asking for the "key" whose "namespace" was /wikipedia/en_id). Speaking about IDs, Metaweb has done a great job in reconciliating entities from different sources and already provides plenty of unique identifiers for its topics. For instance, we could get not only Wikipedia and Freebase own IDs here, but also the ones from Geonames if we wanted to (this is left to the reader as an exercise ;)). If you want to know more about this, just check the Id documentation page on Freebase wiki;
- the mql_filter parameter allows you to specify some constraints to filter data before they are returned by the system. This is very useful for us, as we can put our constraints on geographic coordinates here. I also specified the type /location/location to "cast" results on it, as it is the one which has the geolocation property. Finally, I repeated the constraint on the Wikipedia key which is also present in the output, as not all the topics have this kind of key and the API wants us to filter them away in advance.
Luckily, in this case the results were much more satisfying: only 9 out of 233 cities were not found, giving us a recall higher than 96%. The reasons why those cities were missing follow:
- three cities did not have the specified name as one of their alternative spellings;
- four cities had non-matching coordinates (this can be due either to Metaweb's data or to Yahoo's bounding boxes, however after a quick check it seems that Metaweb's are fine);
- two cities (Buzios and Singapore) just did not exist as cities in Freebase.
The good news is that, apart from the last case, the other ones can be easily fixed just by updating Freebase topics: for instance one city (Benidorm) just did not have any geographic coordinates, so (bow to the mighty power of the crowd, and of Freebase that supports it!) I just added them taking the values from Wikipedia and now the tool works fine with it. Of course, I would not suggest anybody to run my 74-lines script now to reconciliate the WOEIDs of all the cities in the World and then manually fix the empty results, however this gives us hope on the fact that, with some more programming effort, this reconciliation could be possible without too much human involvement.
So, I'm pretty satisfied right now. At least for our small project (which will probably become the subject of one blog post sooner or later ;)) we got what we needed, and then who knows, maybe with the help of someone we could make the script better and start adding WOEIDs to cities in Freebase... what do you think about this?
I have prepared a zip file with all the material I talked about in this post, so you don't have to follow too many links to get all you need. In the zip you will find:
- woe2wp.pl and woe2wpFB.pl, the two perl scripts;
- test*.pl, the two test scripts that run woe2wp or woe2wpFB over the list of WOEIDs provided in the following file;
- woeids.txt, the list of 233 WOEIDs I tested the scripts with;
- output*.txt, the (commented) outputs of the two test scripts.
Here is the zip package. Have fun ;)
Perl Hacks: automatically get info about a movie from IMDB
Ok, I know the title sounds like "hey, I found an easy API and here's how to use it"... well, the post is not much more advanced than this but 1) it does not talk about an API but rather about a Perl package and 2) it is not so trivial, as it does not deal with clean, precise movie titles, but rather with another kind of use case you might happen to witness quite frequently in real life.
Yes, we are talking about pirate video... and I hope that writing this here will bring some kids to my blog searching for something they won't find. Guys, go away and learn to search stuff the proper way... or stay here and learn something useful ;-)
So, the real life use case: you have a directory containing videos you have downloaded or you have been lent by a friend (just in case you don't want to admit you have downloaded them ;-). All the titles are like
The.Best.Movie.Ever(2011).SiLeNT.[dvdrip].md.xvid.whatever_else.avi
and yes, you can easily understand what the movie title is and automatically remove all the other crap, but how can a software can do this? But first of all, why should a software do this?
Well, suppose you are not watching movies from your computer, but rather from a media center. It would be nice if, instead of having a list of ugly filenames, you were presented a list of film posters, with their correct titles and additional information such as length, actors, etc. Moreover, if the information you have about your video files is structured you can easily manage your movie collection, automatically categorizing them by genre, director, year, or whatever you prefer, thus finding them more easily. Ah, and of course you might just be interested in a tool that automatically renames files so that they comply with your naming standards (I know, nerds' life is a real pain...).
What we need, then, is a tool that links a filename (that we suppose contains at least the movie title) to, basically, an id (like the IMDB movie id) that uniquely identifies that movie. Then, from IMDB itself we can get a lot of additional information. The steps we have to perform are two:
- convert an almost unreadable filename in something similar to the original movie title
- search IMDB for that movie title and get information about it
Of course, I expect that not all the results are going to be perfect: filenames might really be too messy or there could be different movies with the same name. However, I think that having a tool that gives you a big help in cleaning your movie collection might be fine even if it's not perfect.
Let's start with point 1: filename cleaning. First of all, you need to have an idea about how files are actually named. To find enough examples, I just did a quick search on google for divx dvdscr dvdrip xvid filetype:txt: it is surprising how many file lists you can find with such a small effort :) Here are some examples of movie titles:
American.Beauty.1999.AC3.iNTERNAL.DVDRip.XviD-xCZ Dodgeball.A.True.Underdog.Story.SVCD.TELESYNC-VideoCD Eternal.Sunshine.Of.The.Spotless.Mind.REPACK.DVDSCr.XViD-DvP
and so on. All the additional keywords that you find together with the movie's title are actually useful ones, as they detail the quality of the video (i.e. svcd vs dvdrip or screener), the group that created it, and so on. However we currently don't need them so we have to find a way to remove them. Moreover, a lot of junk such as punctuation and parentheses are added to most of the file names, so it is very difficult to understand when the movie title ends and the rest begins.
To clean this mess, I have first filtered everything so that only alphanumeric characters are kept and everything else is considered as a separator (this became the equivalent of the tokenizing phase of a document indexer). Then I built a list of stopwords that need to be automatically removed from the filename. The list has been built from the very same file I got the titles from (you can find it here or, if the link is dead, download the file ALL_MOVIES here). Just by counting the occurences of each word with a simple perl script, I came out with a huge list of terms I could easily remove: to give you an idea of it, here's an excerpt of all the terms that occur at least 10 times in that file
129 -> DVDRip 119 -> XviD 118 -> The 73 -> XViD 35 -> DVDRiP 34 -> 2003 33 -> REPACK DVDSCR 30 -> SVCD the 24 -> 2 22 -> xvid 20 -> LiMiTED 19 -> DVL dvdrip 18 -> of A DMT 17 -> LIMITED Of 16 -> iNTERNAL SCREENER 14 -> ALLiANCE 13 -> DiAMOND 11 -> TELESYNC AC3 DVDrip 10 -> INTERNAL and VideoCD in
As you can see, most of the most frequent terms are actually stopwords that can be safely removed without worrying too much about the original titles. I started with this list and then manually added new keywords I found after the first tests. The results are in my blacklist file. Finally, I decided to apply another heuristic to clean filenames: every time a sequence of token ends with a date (starting with 19- or 20-) there are chances that it is just the movie date and not part of the title; thus, this date has to be removed too. Of course, if the title is made up of only that date (i.e. 2010) it is kept. Summarizing, the Perl code used to clean filenames is just the following one:
sub cleanTitle{
my ($dirtyTitle, $blacklist) = @_;
my @cleanTitleArray;
# HEURISTIC #1: everything which is not alphanumeric is a separator;
# HEURISTIC #2: if an extracted word belongs to the blacklist then ignore it;
while ($dirtyTitle =~ /([a-zA-Z0-9]+)/g){
my $word = lc($1); # blacklist is lowercase
if (!defined $$blacklist{$word}){
push @cleanTitleArray, $word;
}
}
# HEURISTIC #3: often movies have a date (year) after the title, remove
# that (if it is not the title of the movie itself!);
my $lastWord = pop(@cleanTitleArray);
my $arraySize = @cleanTitleArray;
if ($lastWord !~ /(19\d\d)|(20\d\d)/ || !$arraySize){
push @cleanTitleArray, $lastWord;
}
return join (" ", @cleanTitleArray);
}
Step 2, instead, consists in sending the query to IMDB and getting information back. Fortunately this is a pretty trivial step, given we have IMDB::Film available! The only thing I had to modify in the package was the function that returns alternative movie titles: it was not working and I also wanted to customize it to return a hash ("language"=>"alt title") instead of an array. I started from an existing patch to the (currently) latest version of IMDB::Film that you can find here, and created my own Film.pm patch (note that the patch has to be applied to the original Film.pm and not to the patched version described in the bug page).
Access to IMDB methods is already well described in the package page. The only addition I made was to my script was the getAlternativeTitle function, which gets all the alternative titles for a movie and returns, in order of priority, the Italian one if it exists, otherwise the international/English one. This is the code:
sub getAlternativeTitle{
my $imdb = shift;
my $altTitle = "";
my $aka = $imdb->also_known_as();
foreach $key (keys %$aka){
# NOTE: currently the default is to return the Italian title,
# otherwise rollback to the first occurrence of International
# or English. Change below here if you want to customize it!
if ($key =~ /^Ital/){
$altTitle = $$aka{$key};
last;
}elsif ($key =~ /^(International|English)/){
$altTitle = $$aka{$key};
}
}
return $altTitle;
}
So, that's basically all. The script has been built to accept only one parameter on the command line. For testing, if the parameter is recognized as an existing filename, the file is opened and parsed for a list of movie titles; otherwise, the string is considered as a movie title to clean and search.
Testing has been very useful to understand if the tool was working well or not. The precision is pretty good, as you can see from the attached file output.txt (if anyone wants to calculate the percentage of right movies... Well, you are welcome!), however I suspect it is kind of biased towards this list, as it was the same one I took the stopwords from. If you have time to waste and want to work on a better, more complete stopwords list I think you have already understood how easy it is to create one... please make it available somewhere! :-)
The full package, with the original script (mt.pl) and its data files is available here. Enjoy!
Perl Hacks: infogain-based term cloud
This is one of the very first tools I have developed in my first year of post-doc. It took a while to publish it as it was not clear what I could disclose of the project that was funding me. Now the project has ended and, after more than one year, the funding company still has not funded anything ;-) Moreover, this is something very far from the final results that we obtained, so I guess I could finally share it.
Rather than a real research tool, this is more like a quick hack that I built up to show how we could use Information Gain to extract "interesting" words from a collection of documents, and term frequencies to show them in a cloud. I have called it a "term cloud" because, even if it looks like the well-known tag clouds, it is not built up with tags but with terms that are automatically extracted from a corpus of documents.

Figure 1: the term cloud built by rain out of a collection of documents about folksonomies.
The tool is called "rain" as it is based on rainbow, an application built on top of the "bow" libraries that performs statistical text classification. The basic idea is that we use two sets of documents: the training set is used to instruct the system about what can be considered "common knowledge"; the test set is used to provide documents about the specific domain of knowledge we are interested in. The result is that the words which more likely discriminate the test set from the training one are selected, and their occurrences are used to build the final cloud.
All is done within a pretty small perl script, which does not do much more than calling the rainbow tool (which has to be installed first!) and using its output to perform calculation and build an HTML page with the generated cloud. You can download the script from these two locations:
- here you can find a barebone version of the script, which only contains the script and few test documents collections. The tool works (that is it does not return errors) even without training data, but will not perform fine unless it is properly trained. You will also have to download and install rainbow before you can use it;
- here you can find an "all inclusive" version of the script. It is much bigger but it provides: the ".deb" file to install rainbow (don't be frightened by its release date, it still works with Ubuntu Maverick!), and a training set built by collecting all the posts from the "20_newsgroups" data set.
How can I run the rain tool?
Supposing you are using the "all inclusive" version, that is you already have your training data and rainbow installed, running the tool is easy as writing
perl rain.pl <path_to_test_dir>
The script parameters can be modified within the script itself (see the following excerpt from the script source):
my $TERMS = 50; # size of the pool (top words by infogain)
my $TAGS = 50; # final number of tags (top words by occurrence)
my $SIZENUM = 6; # number of size classes to be used in the HTML document,
# represented as different font sizes in the CSS
my $FIREFOX_BIN = '/usr/bin/firefox'; # path to browser binary
# (if present, firefox will be called to open the HTML file)
my $RAINBOW_BIN = '/usr/bin/rainbow'; # path to rainbow binary
my $DIR_MODEL = './results/model'; # used internally by rainbow
my $DIR_DATA = './train'; # path to training dir
my $DIR_TEST = $ARGV[0]; # path to test dir
my $FILE_STOPLIST = './stopwords.txt'; # stopwords file
my $FILE_TMPDATA = './results/data.txt'; # file where data generated
# by rainbow will be dumped
my $HTML_TEMPLATE = './template.html'; # template file used to generate the
# tag-cloud html page
my $HTML_OUTPUT = './results/output.html'; # final html page
As you can see, there are quite a lot of parameters but the script can also be run just out of the box: for instance, if you type
perl rain.pl ./test/folksonomies
you will see the cloud shown in Figure 1. And now, here is another term cloud built using my own blog posts as a text corpus:

Perl Hacks: a bot for Google Scholar
Lately I was asked to write a bot which allowed people to easily query Google Scholar and get citations for a person/paper. I wrote this little perl script which requires two parameters: the name of the author and the paper title. It then queries Scholar and returns the number of citations for that paper. Quick and easy! Unfortunately Scholar data are not always consistent, but they are still helpful in some way... And well, of course Publish or Perish is a better tool if you want to know statistics about your publications ;-)
Perl Hacks: del.icio.us scraper
At last, I built it: a working, quite stable del.icio.us scraper. I needed a dataset big enough to make some experiments on it (for a research project I'll talk you about sooner or later), so I had to create something which would not only allow me to download my stuff (like with del.icio.us API), but also data from other users connected with me.
Even if it's a first release, I have tested the script quite much in these days and it's stable enough to let you backup your data and get some more if you're doing research on this topic (BTW, if so let me know, we might exchange some ideas ;-) Here are some of its advantages:
- it just needs a list of users to start and then downloads all their bookmarks
- it saves data inside a DB, so you can query them, export them in any format, do some data mining and so on
- it runs politely, with a 5 seconds sleep between page downloads, so to avoid bombing del.icio.us website with requests
- it supports the use of a proxy
- it's very tweakable: most of its parameters can be easily changed
- it's almost ready for a distributed version (that is, it supports table locking so you can run many clients which connect to a centralized database)
Of course, it's far from being perfect:
- code is still quite messy: probably a more modular version would be easier to update (perl coders willing to give a hand are welcome, of course!)
- I haven't tried the "distributed version" yet, so it just works in theory ;-)
- it's sloooow, especially compared to the huge size of del.icio.us: at the beginning of this month, they said they had about 1.5 million users, and I don't believe that a single client will be able to get much more than few thousand users per day (but do you need more?)
- the way it is designed, the database grows quite quickly and interesting queries won't be very fast if you download many users (DB specialists willing to give a hand are welcome, of course!)
- the program misses a function to harvest users, so you have to provide the list of users you want to download manually. Actually, I made mine with another scraper but I did not want to provide, well, both the gun and the bullets to everyone. I'm sure someone will have something to say about this, but hey, it takes you less time to write your ad-hoc scraper than to add an angry comment here, so don't ask me to give you mine
That's all. You'll find the source code here, have phun ;)
Perl Hacks: K-Means
Well, this probably isn't a best-selling app, but it might be useful for some who, like me, have to explain how k-means clustering algorithm works or to prepare exercises about it. Also, this works as an example on how to embed latex formulas inside images with Perl: the script actually draws the plane (with points and centroids) inside an image, then generates latex formulas which describe the algorithm evolution, compiles them into images with tex2im and embeds them inside the main picture. The final output is made of many different pictures, one for each step of the algorithm, similar to the following one:
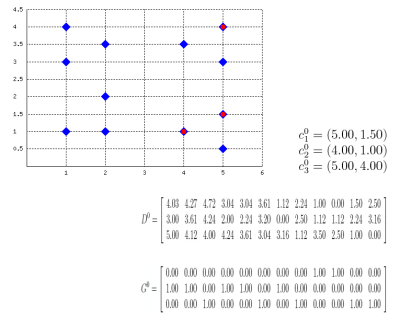
Of course, the script is still far from perfect but (again, of course) the source code is provided so you can change/correct/ameliorate it. To run it you will also need text2im, which is downloadable here (a big THANK YOU to Andreas Reigber who created this nice shell script), and of course latex stuff.
Perl Hacks: more sudokus
Hi all,
incredibly, I got messages asking for more sudokus: aren't you satisfied with the ones harvested from Daily Sudoku? Well... once a script like SukaSudoku is ready, the only work that has to be done is to create a new wrapper for another website! Let's take, for instance, Number Logic site: here's a new perl script which inherits most of its code from SukaSudoku and extracts information from Number Logic. Just copy it over the old "suka.pl" file and double the number of sudokus to play with.
Perl Hacks: quotiki bot
I like quotiki. I like fortunes. Why not make a bot which downloads a random quote from quotiki and shows it on my computer? Here's a little perl bot which does exactly this. It's very short and easy, so I guess this could be a good starting point for beginners.
And, by the way:
"Age is an issue of mind over matter. If you don't mind, it doesn't matter."
-- Mark Twain
;)
Perl Hacks: Google search
I'm at page 14 inside Google results for the search string "perl hacks". Well, at least in google.it which is where I'm automatically redirected...
Who bothers? Well, not even me, I was just curious about it. How did I do it? Well, of course automatically with a perl bot!
Here it is. You call it passing two parameters from the command line: the first one is the search string (ie. "\"perl hacks\""), the second one is (part of) the title of the page (ie. "mala::home"). Then the program connects to Google, searches for the search string and then finds at which page the second string occurs.
Probably someone noticed the filename ends with "02". Is there a "01" out there too? Of course there is: it's a very similar version which doesn't search only inside titles but also in the whole snippet of text related to the search result. Less precise, but a little more flexible.