New “hacks” series
It all started last winter, when a couple of old friends asked me if I wanted to help in writing articles for an Italian magazine. The zine was targeted at young people willing to learn something more about what is going on inside their computer: some would call them wannabe hackers, I'd prefer to think about them as potential reversers ;-)
Why did I accept this work? The reasons are many, including the deep respect I have for these friends, some nostalgia of good old times, the fact that the magazine has no ads, and finally the right to redistribute my articles online.So here they are, a collection of introductory texts that I hope will be useful for someone. If you are already an expert you will probably find nothing interesting here, but I like to think that few people really are as expert as they think.. ;)
So, how does it work? Well, I don't have much time so I usually write a very short article each month. The original article is always in Italian, so I have to translate it (any help is more than welcome!). I already have a buffer long enough to keep you busy for a while, so here is my plan: one article every other Sunday for some months, then we'll see (yeah, this does not sound like a very detailed plan :)).
Shall we start?
Perl Hacks: a bot for Google Scholar
Lately I was asked to write a bot which allowed people to easily query Google Scholar and get citations for a person/paper. I wrote this little perl script which requires two parameters: the name of the author and the paper title. It then queries Scholar and returns the number of citations for that paper. Quick and easy! Unfortunately Scholar data are not always consistent, but they are still helpful in some way... And well, of course Publish or Perish is a better tool if you want to know statistics about your publications ;-)
Perl Hacks: del.icio.us scraper
At last, I built it: a working, quite stable del.icio.us scraper. I needed a dataset big enough to make some experiments on it (for a research project I'll talk you about sooner or later), so I had to create something which would not only allow me to download my stuff (like with del.icio.us API), but also data from other users connected with me.
Even if it's a first release, I have tested the script quite much in these days and it's stable enough to let you backup your data and get some more if you're doing research on this topic (BTW, if so let me know, we might exchange some ideas ;-) Here are some of its advantages:
- it just needs a list of users to start and then downloads all their bookmarks
- it saves data inside a DB, so you can query them, export them in any format, do some data mining and so on
- it runs politely, with a 5 seconds sleep between page downloads, so to avoid bombing del.icio.us website with requests
- it supports the use of a proxy
- it's very tweakable: most of its parameters can be easily changed
- it's almost ready for a distributed version (that is, it supports table locking so you can run many clients which connect to a centralized database)
Of course, it's far from being perfect:
- code is still quite messy: probably a more modular version would be easier to update (perl coders willing to give a hand are welcome, of course!)
- I haven't tried the "distributed version" yet, so it just works in theory ;-)
- it's sloooow, especially compared to the huge size of del.icio.us: at the beginning of this month, they said they had about 1.5 million users, and I don't believe that a single client will be able to get much more than few thousand users per day (but do you need more?)
- the way it is designed, the database grows quite quickly and interesting queries won't be very fast if you download many users (DB specialists willing to give a hand are welcome, of course!)
- the program misses a function to harvest users, so you have to provide the list of users you want to download manually. Actually, I made mine with another scraper but I did not want to provide, well, both the gun and the bullets to everyone. I'm sure someone will have something to say about this, but hey, it takes you less time to write your ad-hoc scraper than to add an angry comment here, so don't ask me to give you mine
That's all. You'll find the source code here, have phun ;)
Perl Hacks: K-Means
Well, this probably isn't a best-selling app, but it might be useful for some who, like me, have to explain how k-means clustering algorithm works or to prepare exercises about it. Also, this works as an example on how to embed latex formulas inside images with Perl: the script actually draws the plane (with points and centroids) inside an image, then generates latex formulas which describe the algorithm evolution, compiles them into images with tex2im and embeds them inside the main picture. The final output is made of many different pictures, one for each step of the algorithm, similar to the following one:
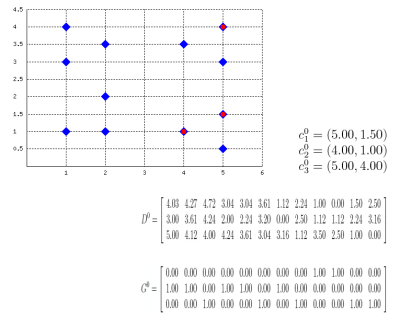
Of course, the script is still far from perfect but (again, of course) the source code is provided so you can change/correct/ameliorate it. To run it you will also need text2im, which is downloadable here (a big THANK YOU to Andreas Reigber who created this nice shell script), and of course latex stuff.
Perl Hacks: more sudokus
Hi all,
incredibly, I got messages asking for more sudokus: aren't you satisfied with the ones harvested from Daily Sudoku? Well... once a script like SukaSudoku is ready, the only work that has to be done is to create a new wrapper for another website! Let's take, for instance, Number Logic site: here's a new perl script which inherits most of its code from SukaSudoku and extracts information from Number Logic. Just copy it over the old "suka.pl" file and double the number of sudokus to play with.
Perl Hacks: quotiki bot
I like quotiki. I like fortunes. Why not make a bot which downloads a random quote from quotiki and shows it on my computer? Here's a little perl bot which does exactly this. It's very short and easy, so I guess this could be a good starting point for beginners.
And, by the way:
"Age is an issue of mind over matter. If you don't mind, it doesn't matter."
-- Mark Twain
;)
Perl Hacks: Google search
I'm at page 14 inside Google results for the search string "perl hacks". Well, at least in google.it which is where I'm automatically redirected...
Who bothers? Well, not even me, I was just curious about it. How did I do it? Well, of course automatically with a perl bot!
Here it is. You call it passing two parameters from the command line: the first one is the search string (ie. "\"perl hacks\""), the second one is (part of) the title of the page (ie. "mala::home"). Then the program connects to Google, searches for the search string and then finds at which page the second string occurs.
Probably someone noticed the filename ends with "02". Is there a "01" out there too? Of course there is: it's a very similar version which doesn't search only inside titles but also in the whole snippet of text related to the search result. Less precise, but a little more flexible.
Perl Hacks: Googleicious!
At last, here's my little googleicious, my first attempt at merging google results with del.icio.us tags. I did it some months ago to see if I could automatically retrieve information from del.icio.us. Well... it's possible :)
What does this script do? It takes a word (or a collection of words) from the command line and searches for it on google; then it takes the search results, extracts URLs from it and searches for them within del.icio.us, showing the tags that have been used to classify them. Even if the script is quite simple, there are many details you can infer from its output:
- you can see how many top results in Google are actually interesting for people
- you can use tags to give meaning to some obscure words (try for instance ESWC and you'll see it's a conference about semantic web, or screener and you'll learn it's not a term used only by movie rippers)
- starting from the most used tags returned by del.icio.us, you can search for similar URLs which haven't been returned by Google
Now some notes:
- I believe this is very near to a limit both Google and del.icio.us don't want you to cross, so please behave politely and avoid bombing them with requests
- For the very same reason, this version is quite limited (it just takes the first page of results) but lacks some more controls I put in later versions such as sleep time to avoid request bursts. So, again, be polite please ^__^
- I know that probably one zillion people have already used the term googleicious and I don't want to be considered as its inventor. I just invented the script, so if you don't like the name just call it foobar or however you like: it will run anyway.
Ah, yes, the code is here!
Perl Hacks: SukaSudoku!
Hi everybody :)
As I decided to post one "perl hack" each week, and as after two posts I lost my inspiration, I've decided to recycle an old project which hasn't been officially published yet. Its name is sukasudoku, and as the name implies it sucks sudokus from a website (http://www.dailysudoku.com) and saves them on your disk.
BUT...
Hah! It doesn't just "save them on your disk", but creates a nice book in PDF with all the sudokus it has downloaded. Then you can print the book, bind it and either play your beloved sudokus wherever you want or give it to your beloved ones as a beautiful, zero-cost Xmas gift.
Of course, the version I publish here is limited just to avoid having every script kiddie download the full archive without efforts. But you have the source, and you have the knowledge. So what's the problem?
The source file is here for online viewing, but to have a working version you should download the full package. In the package you will find:
- book and clean, two shell scripts to create the book from the LaTeX source (note: of course, you need latex installed in your system to make it work!) and to remove all the junk files from the current dir
- sudoku.sty, the LaTeX package used to create sudoku grids
- suka.pl, the main script
- tpl_sudoku.tex, the template that will be used to create the latex document containing sudokus
Perl Hacks: ESSID-dependant networking startup
Problem: you have a laptop, which has to work with different wifi networks. For each one, you need different startup options (ie. you have to start openvpn at work, you have to set encryption at home, you just have to run networking in all other cases). You would like to autodetect the network you're in and run configs accordingly.
Solution: instead of the usual networking startup script, run this one. Then create some scripts inside /etc/nw directory, one for each ESSID network you've specified inside the Perl script and a default one. For instance:
/etc/nw/wlanHOME:
#!/bin/sh iwconfig eth1 essid wlanHOME iwconfig eth1 key 917AD823B4EA3395E214BC258B /etc/init.d/networking start
/etc/nw/wlanWORK:
#!/bin/sh /etc/init.d/networking start /etc/init.d/openvpn start
/etc/nw/default:
#!/bin/sh /etc/init.d/networking start
... of course it's not perfect, but it's quite easy to understand and I hope that with the code under your hands you'll be able to create something useful.
Have phun,
+mala