New paper: Exploiting tag similarities to discover synonyms and homonyms in folksonomies
[This is post number 5 of the "2012 publications" series. Read here if you want to know more about this]
I have posted a new publication in the Research page:
Davide Eynard, Luca Mazzola, and Antonina Dattolo. Exploiting tag similarities to discover synonyms and homonyms in folksonomies.
"Tag-based systems are widely available thanks to their intrinsic advantages, such as self-organization, currency, and ease of use. Although they represent a precious source of semantic metadata, their utility is still limited. The inherent lexical ambiguities of tags strongly affect the extraction of structured knowledge and the quality of tag-based recommendation systems. In this paper, we propose a methodology for the analysis of tag-based systems, addressing tag synonymy and homonymy at the same time in a holistic approach: in more detail, we exploit a tripartite graph to reduce the problem of synonyms and homonyms; we apply a customized version of Tag Context Similarity to detect them, overcoming the limitations of current similarity metrics; finally, we propose the application of an overlapping clustering algorithm to detect contexts and homonymies, then evaluate its performances, and introduce a methodology for the interpretation of its results."
The editor (John Wiley & Sons, Ltd.) requested not to directly make the paper available online. However I have "the personal right to send or transmit individual copies of this PDF to colleagues upon their specific request provided no fee is charged, and further-provided that there is no systematic distribution of the Contribution, e.g. posting on a listserv, website or automated delivery." So, just drop me an email if you want to read it and I will send it to you (in a non-systematic way ;-))
New paper: Harvesting User Generated Picture Metadata To Understand Destination Similarity
[This is post number 4 of the "2012 publications" series. Read here if you want to know more about this]
I have posted a new publication in the Research page:
Alessandro Inversini, Davide Eynard. Harvesting User Generated Picture Metadata To Understand Destination Similarity.
This is an extension of a previous work for the Journal of Information Technology & Tourism, providing additional and updated information gathered with new user surveys.
"Pictures about tourism destinations are part of the contents shared online through social media by travelers. User-generated pictures shared in social networks carry additional information such as geotags and user descriptions of places that can be used to identify groups of similar destinations. This article investigates the possibility of defining destination similarities relying on implicit information already shared on the Web. Additionally, the possibility of recommending one city on the basis of a given set of pictures is explored. Flickr. com was used as a case study as it represents the most popular picture sharing website. The results indicate that it is possible to group similar destinations according to picture-related information, and recommending destinations without requiring users' profiles or sets of explicit preferences.".
Slides for “An integrated approach to discover tag semantics”
The slides of my presentation at SAC 2011 are available on SlideShare:
Just to have an idea on what the presentation is about, here's an excerpt of the paper's abstract and the link to the paper itself.
New paper: An integrated approach to discover tag semantics
Antonina Dattolo, Davide Eynard, and Luca Mazzola. An Integrated Approach to Discover Tag Semantics. 26th Annual ACM Symposium on Applied Computing, vol. 1, pp. 814-820. Taichung, Taiwan, March 2011. From the abstract:
"Tag-based systems have become very common for online classification thanks to their intrinsic advantages such as self-organization and rapid evolution. However, they are still affected by some issues that limit their utility, mainly due to the inherent ambiguity in the semantics of tags. Synonyms, homonyms, and polysemous words, while not harmful for the casual user, strongly affect the quality of search results and the performances of tag-based recommendation systems. In this paper we rely on the concept of tag relatedness in order to study small groups of similar tags and detect relationships between them. This approach is grounded on a model that builds upon an edge-colored multigraph of users, tags, and resources. To put our thoughts in practice, we present a modular and extensible framework of analysis for discovering synonyms, homonyms and hierarchical relationships amongst sets of tags. Some initial results of its application to the delicious database are presented, showing that such an approach could be useful to solve some of the well known problems of folksonomies".
Paper is available here. Enjoy! ;)
New (old) paper: “GVIS: A framework for graphical mashups of heterogeneous sources to support data interpretation”
I know this is not a recent paper (it has been presented in May), but I am slowly doing a recap of what I have done during the last year and this is one of the updates you might have missed. "GVIS: A framework for graphical mashups of heterogeneous sources to support data interpretation", by Luca Mazzola, me, and Riccardo Mazza, is the first paper (and definitely not the last, as I have already written another!) with Luca, and it has been a great fun for me. We had a chance to merge our works (his modular architecture and my semantic models and tools) to obtain something new, that is the visualization of a user profile based on her browsing history and tags retrieved from Delicious.
Curious about it? You can find the document here (local copy: here) and the slides of Luca's presentation here.
Some del.icio.us stats (part 1)
I've started to run some analyses on the dataset I scraped from del.icio.us. The first thing I absolutely _had_ to do, of course, was to build the well-known power law distribution graph: I didn't have many doubts about it, but when I saw how well it worked I was quite satisfied ;-)
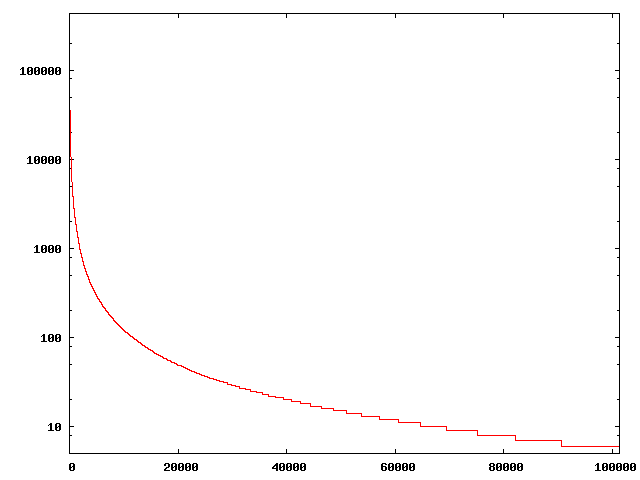
Then I tried to do something (I considered) more interesting, that is finding which percentage of tags actually belongs to a more "meaningful", specific set like WordNet database. To accomplish this, I built some scripts which used WordNet::Similarity and WordNet::QueryData packages to query WordNet and check for the existance of tags (or , better, their stemmed versions). Data are encouraging, giving 114 recognized words out of the 140 most used tags (81.43%). Notice that these do not include, for instance, tags like "web2.0", "howto", "javascript" and "firefox".
But what about less used tags? Our hypothesis was that this value should lower falling down the power law curve, towards the long tail, that is most used tags should also often be present inside WordNet. Well, here are the data:

On the horizontal axis there are tags, ordered by usage from the most used ones. Tags are packed in groups of size 1000, and for each group you can read, on the vertical axis, how many of them are present inside Wordnet. So, for instance, of the first 1000 tags 764 are recognized (76.4%), for the next thousand 671 (67.1%) and so on. The long tail has values within a range which is about 3~5%.
I'll soon post data and scripts, in the meanwhile if you have comments (here or by mail) I'll be glad to read them. ^__^
Perl Hacks: del.icio.us scraper
At last, I built it: a working, quite stable del.icio.us scraper. I needed a dataset big enough to make some experiments on it (for a research project I'll talk you about sooner or later), so I had to create something which would not only allow me to download my stuff (like with del.icio.us API), but also data from other users connected with me.
Even if it's a first release, I have tested the script quite much in these days and it's stable enough to let you backup your data and get some more if you're doing research on this topic (BTW, if so let me know, we might exchange some ideas ;-) Here are some of its advantages:
- it just needs a list of users to start and then downloads all their bookmarks
- it saves data inside a DB, so you can query them, export them in any format, do some data mining and so on
- it runs politely, with a 5 seconds sleep between page downloads, so to avoid bombing del.icio.us website with requests
- it supports the use of a proxy
- it's very tweakable: most of its parameters can be easily changed
- it's almost ready for a distributed version (that is, it supports table locking so you can run many clients which connect to a centralized database)
Of course, it's far from being perfect:
- code is still quite messy: probably a more modular version would be easier to update (perl coders willing to give a hand are welcome, of course!)
- I haven't tried the "distributed version" yet, so it just works in theory ;-)
- it's sloooow, especially compared to the huge size of del.icio.us: at the beginning of this month, they said they had about 1.5 million users, and I don't believe that a single client will be able to get much more than few thousand users per day (but do you need more?)
- the way it is designed, the database grows quite quickly and interesting queries won't be very fast if you download many users (DB specialists willing to give a hand are welcome, of course!)
- the program misses a function to harvest users, so you have to provide the list of users you want to download manually. Actually, I made mine with another scraper but I did not want to provide, well, both the gun and the bullets to everyone. I'm sure someone will have something to say about this, but hey, it takes you less time to write your ad-hoc scraper than to add an angry comment here, so don't ask me to give you mine
That's all. You'll find the source code here, have phun ;)
Bibsonomy
As you probably have noticed yet just by giving a look at my About page, I'm using Bibsonomy as an online tool to manage bibliographies for my (erm... future?) papers. If you use BibTeX (or EndNote) for your bibliographies this is quite a useful tool. With it you can:
- Save references to the papers/websites you have read all in one place
- Save all the bibliography-related information in a standard, widely used format
- Tag publications: this doesn't only mean you can easily find them later, but also that you can share them with others, find new ones, find new people interested in the same stuff and so on (soon: an article about tags and folksonomies, I promise)
- Easily export publication lists in BibTeX format, ready to include in your papers
This export feature is particularly useful: you can manage your bibliographies directly on the website and then export them (or a part of them) in few clicks. Even better: you can do that even without clicking at all! Try this:
wget "http://www.bibsonomy.org/bib/user/deynard?items=100" -O bibs.bib
You've just downloaded my whole collection inside one "bibs.bib" file, ready to be included in your LaTeX document. The items parameter allows you to specify how many publications you want to download: yes, it sounds silly (why would you want only the first n items?)
Of course, if you like you can just download items tagged as "tagging" with this URL:
http://www.bibsonomy.org/bib/user/deynard/tagging
You can join tags like in this URL:
http://www.bibsonomy.org/bib/user/deynard/tagging+ontology
And of course, you can substitute wget with lynx:
lynx -dont_wrap_pre -dump "http://www.bibsonomy.org/bib/user/deynard?items=100" > bibs2.bib
Well, that's all for now. If you happen to find any interesting hacks lemme know ;)