Who’s this guy?
Well, I'm not exactly interested in him, but...
http://del.icio.us/brentparker
Haven't you noticed anything strange inside his del.icio.us page?
No? Well, compare it with another user (statistically, you should find a "normal" one more easily).
Is he alone, or are there other "bugged users" inside del.icio.us?
Ok, ok, I'll stop reading my scraper's log ;-)
Perl Hacks: del.icio.us scraper
At last, I built it: a working, quite stable del.icio.us scraper. I needed a dataset big enough to make some experiments on it (for a research project I'll talk you about sooner or later), so I had to create something which would not only allow me to download my stuff (like with del.icio.us API), but also data from other users connected with me.
Even if it's a first release, I have tested the script quite much in these days and it's stable enough to let you backup your data and get some more if you're doing research on this topic (BTW, if so let me know, we might exchange some ideas ;-) Here are some of its advantages:
- it just needs a list of users to start and then downloads all their bookmarks
- it saves data inside a DB, so you can query them, export them in any format, do some data mining and so on
- it runs politely, with a 5 seconds sleep between page downloads, so to avoid bombing del.icio.us website with requests
- it supports the use of a proxy
- it's very tweakable: most of its parameters can be easily changed
- it's almost ready for a distributed version (that is, it supports table locking so you can run many clients which connect to a centralized database)
Of course, it's far from being perfect:
- code is still quite messy: probably a more modular version would be easier to update (perl coders willing to give a hand are welcome, of course!)
- I haven't tried the "distributed version" yet, so it just works in theory ;-)
- it's sloooow, especially compared to the huge size of del.icio.us: at the beginning of this month, they said they had about 1.5 million users, and I don't believe that a single client will be able to get much more than few thousand users per day (but do you need more?)
- the way it is designed, the database grows quite quickly and interesting queries won't be very fast if you download many users (DB specialists willing to give a hand are welcome, of course!)
- the program misses a function to harvest users, so you have to provide the list of users you want to download manually. Actually, I made mine with another scraper but I did not want to provide, well, both the gun and the bullets to everyone. I'm sure someone will have something to say about this, but hey, it takes you less time to write your ad-hoc scraper than to add an angry comment here, so don't ask me to give you mine
That's all. You'll find the source code here, have phun ;)
Perl Hacks: K-Means
Well, this probably isn't a best-selling app, but it might be useful for some who, like me, have to explain how k-means clustering algorithm works or to prepare exercises about it. Also, this works as an example on how to embed latex formulas inside images with Perl: the script actually draws the plane (with points and centroids) inside an image, then generates latex formulas which describe the algorithm evolution, compiles them into images with tex2im and embeds them inside the main picture. The final output is made of many different pictures, one for each step of the algorithm, similar to the following one:
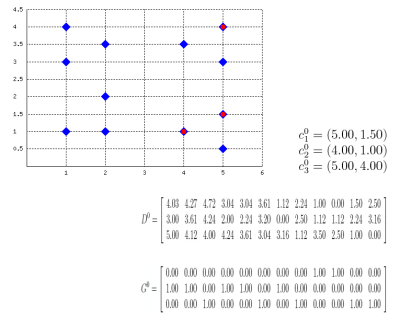
Of course, the script is still far from perfect but (again, of course) the source code is provided so you can change/correct/ameliorate it. To run it you will also need text2im, which is downloadable here (a big THANK YOU to Andreas Reigber who created this nice shell script), and of course latex stuff.