Using semantics and user participation to customize personalization
At last, my HPL report has been officially approved for external publication! However, for some strange reason it still does not appear in the 2008 report list... Mah!
Btw, if you ever heard me speakin' about my RDFMonkey creature this is the paper you have to read: you can access the page @HPL here, or download a copy directly from here. Enjoy! :)
Improving Search and Navigation by Combining Ontologies and Social Tags
Paper has been accepted! Just quoting Giorgio Orsi's post (who, in turn, is quoting the abstract):
"The Semantic Web has the ambitious goal of enabling complex autonomous applications to reason on a machine-processable version of the World Wide Web. This, however, would require a coordinated effort not easily achievable in practice. On the other hand, spontaneous communities, based on social tagging, recently achieved noticeable consensus and diffusion. The goal of the TagOnto system is to bridge between these two realities by automatically mapping (social) tags to more structured domain ontologies, thus, providing assistive, navigational features typical of the Semantic Web. These novel searching and navigational capabilities are complementary to more traditional search engine functionalities. The system, and its intuitive AJAX interface, are released and demonstrated on-line."
Paper is available here.
July 01, 2008: talk @HPL
Cool talk, had a lot of useful feedbacks and suggestions! :-)
Transversal projects
I recently worked on some transversal project for our recently born PhDEI Association. It's a PhD Alumni association for our department and we set up a very basic website (that, we hope, will grow with the contributions of other students), we are organizing a social/scientific event where everyone will have a chance to present his work and know others, and we had some talks presenting transversal topics that could be useful for all of us. I gave two talks:
Material is available on the PhDEI website, just by clicking on the two links above here.
Exploiting user gratification for collaborative semantic annotation
I had a paper accepted at SWUI 2008. Cool! I was really happy to see there actually exists someone interested in making the SW usable by people ;-). Both the presentations and the breakout session were very interesting, so the workshop was well worth the trip. Here are my talk slides:
Site updates
Just a little update on what's goin' on:
- New page: Research
- New slides: I've uploaded some old and new presentations to slideshare, hoping they might be useful to some other PhD student. The topics are very different, as most of them are related to some projects I had to prepare for my courses. The titles follow, choose the one that teases you most ;-)
Alive and kickin
Yes, I know, I should update this website more often. But I've been quite busy lately with... erm... stuff :-)
What did I do?
- in June, I participated to ESWC2007 and presented my poster at the Phd Symposium (paper here, poster here)
- from June, 15th to September, 15th I've been a summer intern at HP Labs, Palo Alto. It's been a great experience and after three months of work I came up with a nice project (and now that Google has opened IMAP access my app is automatically compatible with zillions of email accounts!)
- in September another poster presentation with my name on it came out. Well, I have to be honest: my ex-student (and now coworker) David Laniado did that work for his Master Thesis... but some (I believe good) ideas actually came from me ;-)
- currently I'm working on my minor research project (which is about performances of Intrusion Detection Systems and ways to exploit them to do IDS evasion) and on lots of completely unuseful bureaucratic paperwork for my end-of-year evaluation.
Well, of course there is something else, but I won't write everything in just one post, right? ;-)
Perl Hacks: a bot for Google Scholar
Lately I was asked to write a bot which allowed people to easily query Google Scholar and get citations for a person/paper. I wrote this little perl script which requires two parameters: the name of the author and the paper title. It then queries Scholar and returns the number of citations for that paper. Quick and easy! Unfortunately Scholar data are not always consistent, but they are still helpful in some way... And well, of course Publish or Perish is a better tool if you want to know statistics about your publications ;-)
Some del.icio.us stats (part 1)
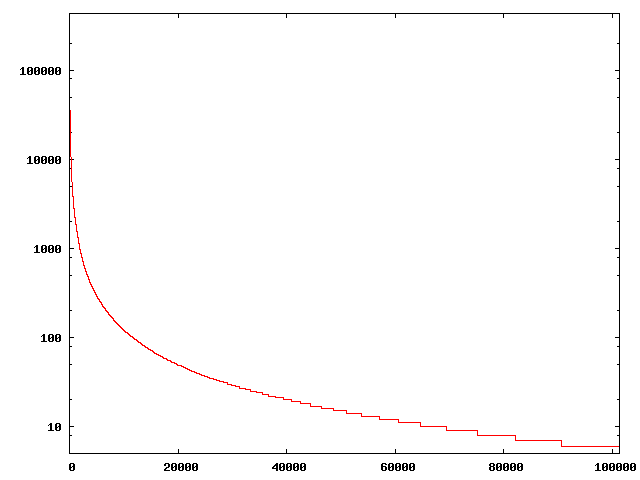
I've started to run some analyses on the dataset I scraped from del.icio.us. The first thing I absolutely _had_ to do, of course, was to build the well-known power law distribution graph: I didn't have many doubts about it, but when I saw how well it worked I was quite satisfied ;-)
Then I tried to do something (I considered) more interesting, that is finding which percentage of tags actually belongs to a more "meaningful", specific set like WordNet database. To accomplish this, I built some scripts which used WordNet::Similarity and WordNet::QueryData packages to query WordNet and check for the existance of tags (or , better, their stemmed versions). Data are encouraging, giving 114 recognized words out of the 140 most used tags (81.43%). Notice that these do not include, for instance, tags like "web2.0", "howto", "javascript" and "firefox".
But what about less used tags? Our hypothesis was that this value should lower falling down the power law curve, towards the long tail, that is most used tags should also often be present inside WordNet. Well, here are the data:

On the horizontal axis there are tags, ordered by usage from the most used ones. Tags are packed in groups of size 1000, and for each group you can read, on the vertical axis, how many of them are present inside Wordnet. So, for instance, of the first 1000 tags 764 are recognized (76.4%), for the next thousand 671 (67.1%) and so on. The long tail has values within a range which is about 3~5%.
I'll soon post data and scripts, in the meanwhile if you have comments (here or by mail) I'll be glad to read them. ^__^