New (old) paper: “GVIS: A framework for graphical mashups of heterogeneous sources to support data interpretation”
I know this is not a recent paper (it has been presented in May), but I am slowly doing a recap of what I have done during the last year and this is one of the updates you might have missed. "GVIS: A framework for graphical mashups of heterogeneous sources to support data interpretation", by Luca Mazzola, me, and Riccardo Mazza, is the first paper (and definitely not the last, as I have already written another!) with Luca, and it has been a great fun for me. We had a chance to merge our works (his modular architecture and my semantic models and tools) to obtain something new, that is the visualization of a user profile based on her browsing history and tags retrieved from Delicious.
Curious about it? You can find the document here (local copy: here) and the slides of Luca's presentation here.
Some del.icio.us stats (part 1)
I've started to run some analyses on the dataset I scraped from del.icio.us. The first thing I absolutely _had_ to do, of course, was to build the well-known power law distribution graph: I didn't have many doubts about it, but when I saw how well it worked I was quite satisfied ;-)
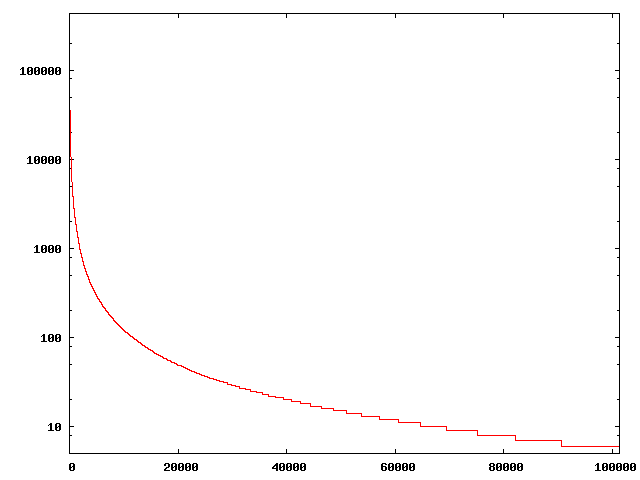
Then I tried to do something (I considered) more interesting, that is finding which percentage of tags actually belongs to a more "meaningful", specific set like WordNet database. To accomplish this, I built some scripts which used WordNet::Similarity and WordNet::QueryData packages to query WordNet and check for the existance of tags (or , better, their stemmed versions). Data are encouraging, giving 114 recognized words out of the 140 most used tags (81.43%). Notice that these do not include, for instance, tags like "web2.0", "howto", "javascript" and "firefox".
But what about less used tags? Our hypothesis was that this value should lower falling down the power law curve, towards the long tail, that is most used tags should also often be present inside WordNet. Well, here are the data:

On the horizontal axis there are tags, ordered by usage from the most used ones. Tags are packed in groups of size 1000, and for each group you can read, on the vertical axis, how many of them are present inside Wordnet. So, for instance, of the first 1000 tags 764 are recognized (76.4%), for the next thousand 671 (67.1%) and so on. The long tail has values within a range which is about 3~5%.
I'll soon post data and scripts, in the meanwhile if you have comments (here or by mail) I'll be glad to read them. ^__^
Who’s this guy?
Well, I'm not exactly interested in him, but...
http://del.icio.us/brentparker
Haven't you noticed anything strange inside his del.icio.us page?
No? Well, compare it with another user (statistically, you should find a "normal" one more easily).
Is he alone, or are there other "bugged users" inside del.icio.us?
Ok, ok, I'll stop reading my scraper's log ;-)
Perl Hacks: del.icio.us scraper
At last, I built it: a working, quite stable del.icio.us scraper. I needed a dataset big enough to make some experiments on it (for a research project I'll talk you about sooner or later), so I had to create something which would not only allow me to download my stuff (like with del.icio.us API), but also data from other users connected with me.
Even if it's a first release, I have tested the script quite much in these days and it's stable enough to let you backup your data and get some more if you're doing research on this topic (BTW, if so let me know, we might exchange some ideas ;-) Here are some of its advantages:
- it just needs a list of users to start and then downloads all their bookmarks
- it saves data inside a DB, so you can query them, export them in any format, do some data mining and so on
- it runs politely, with a 5 seconds sleep between page downloads, so to avoid bombing del.icio.us website with requests
- it supports the use of a proxy
- it's very tweakable: most of its parameters can be easily changed
- it's almost ready for a distributed version (that is, it supports table locking so you can run many clients which connect to a centralized database)
Of course, it's far from being perfect:
- code is still quite messy: probably a more modular version would be easier to update (perl coders willing to give a hand are welcome, of course!)
- I haven't tried the "distributed version" yet, so it just works in theory ;-)
- it's sloooow, especially compared to the huge size of del.icio.us: at the beginning of this month, they said they had about 1.5 million users, and I don't believe that a single client will be able to get much more than few thousand users per day (but do you need more?)
- the way it is designed, the database grows quite quickly and interesting queries won't be very fast if you download many users (DB specialists willing to give a hand are welcome, of course!)
- the program misses a function to harvest users, so you have to provide the list of users you want to download manually. Actually, I made mine with another scraper but I did not want to provide, well, both the gun and the bullets to everyone. I'm sure someone will have something to say about this, but hey, it takes you less time to write your ad-hoc scraper than to add an angry comment here, so don't ask me to give you mine
That's all. You'll find the source code here, have phun ;)