Some del.icio.us stats (part 1)
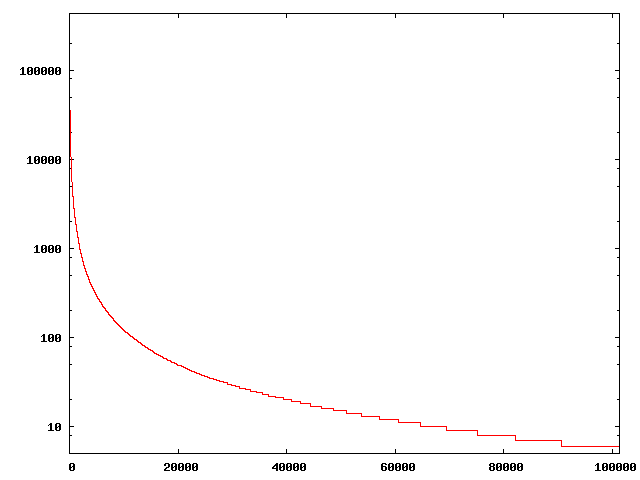
I've started to run some analyses on the dataset I scraped from del.icio.us. The first thing I absolutely _had_ to do, of course, was to build the well-known power law distribution graph: I didn't have many doubts about it, but when I saw how well it worked I was quite satisfied ;-)
Then I tried to do something (I considered) more interesting, that is finding which percentage of tags actually belongs to a more "meaningful", specific set like WordNet database. To accomplish this, I built some scripts which used WordNet::Similarity and WordNet::QueryData packages to query WordNet and check for the existance of tags (or , better, their stemmed versions). Data are encouraging, giving 114 recognized words out of the 140 most used tags (81.43%). Notice that these do not include, for instance, tags like "web2.0", "howto", "javascript" and "firefox".
But what about less used tags? Our hypothesis was that this value should lower falling down the power law curve, towards the long tail, that is most used tags should also often be present inside WordNet. Well, here are the data:

On the horizontal axis there are tags, ordered by usage from the most used ones. Tags are packed in groups of size 1000, and for each group you can read, on the vertical axis, how many of them are present inside Wordnet. So, for instance, of the first 1000 tags 764 are recognized (76.4%), for the next thousand 671 (67.1%) and so on. The long tail has values within a range which is about 3~5%.
I'll soon post data and scripts, in the meanwhile if you have comments (here or by mail) I'll be glad to read them. ^__^
Leave a comment